
Call us in Seattle
+1 (800) 871-6550
Blog:
eMMCフラッシュメモリー搭載デバイスの消耗推定
Monday, June 28, 2021

フラッシュメモリーは、長年にわたって組み込みシステムにおける重要なトピックとなっています。ほかのストレージ技術と比較して、電子機器のサイズと堅牢さを大幅に向上させることができます。そのほかにも、可動部品がなく、消費電力が削減されることもフラッシュストレージのメリットです。一方で、消費者向け電子機器の分野では、フラッシュメモリーに付随する課題についてはあまり広く言及されていません。例えば、耐久性に限界があることやソフトウェアの複雑さが増すといった課題があります。

図1:サムドライブやSSDカードからSSDと集積回路まで、フラッシュメモリーは日常生活の一部となっています。
図1に示すように、サムドライブ、SDカードやSSDなどデータ格納のための専用デバイスから、スマートフォン、Wi-Fiモデムやスマート電球などの消費者向け電子機器に内蔵されたものまで、フラッシュメモリーは日常生活のいたるところで使用されています。
その例外として象徴的なのは、2001年にリリースされたiPodの初代モデルです。5~10GBのという当時としては大容量なストレージを提供するため、回転するハードディスクを採用したのです。しかし、ある研究結果によると、HDD搭載モデルで確認された故障率は20%を超えたのに対し、フラシュメモリー搭載モデルは10%に満たない故障率を示しました。敏感な可動部品を含む回転するディスクは、機械的な衝撃にうまく対応できません。これが、磁気ディスクスのトレージを搭載した携帯デバイスの故障率に大きく影響するのです。

図 2:2001年にリリースされた初代iPodは、磁気ディスクのストレージが搭載された携帯デバイスの珍しい一例です。
組み込みシステムにおいては、フラッシュを不揮発性メモリーに採用するのが最適な選択です。組み込みLinuxシステムでは、システムオンモジュール(SoM)とシングルボードコンピューター(SBC)に集積回路(IC)を使用するのが慣行となっています。これは、いくつかのmicro SDカードのモデルと比較してデータ破損に対する耐性が高いためです。また、環境振動が決定的な要素となる場合にも、より優れた堅牢さを発揮します。内蔵型フラッシュメモリーを採用したSoMの例としては、ToradexのApalisやColibriファミリーが挙げられます。図3では、MicronのeMMCを搭載したColibri iMX8Xモジュールの拡大図を確認できます。

図 3:Colibri iMX8Xには、MicronのeMMCフラッシュメモリーが搭載されています。
この記事の目的は、オープンソースと占有ソフトウェアの双方を活用してeMMCの消耗度を測定および予想することにより、信頼性の高い組み込みシステムを設計する方法について概要を紹介することです。この動機付けとしては、IoTゲートウェイとデータロガーの必要性が高まっていること、また、信頼性向上あるいは断続的接続を理由に冗長データをオンサイトに保管する要求があることが挙げられます。実用的な実装の詳細では、 Micron eMMC搭載Toradex SoMを使用して、消耗の監視および推定用ソリューションである、を利用する例を示します。
この記事には、広範におよぶ技術の概要と実装に関する詳細情報が含まれます。すでによく理解している情報が含まれているかもしれません。十分な知識を持っている場合などは、ご自分の判断で該当するセクションを飛ばしてお読みください。
技術の概要
話を先に進める前にお断りしておきたいのは、フラッシュメモリーは非常に幅広いトピックである、ということです。フラッシュメモリーの仕組みについて説明する記事を1本書いたとしても総合的な概要について十分には伝えきれないかもしれません。以下は、eMMCの消耗を推定する方法をよく理解できるよう、基礎的知識のみを説明するために書かれました。
この記事では消耗の推定についての理解に必要な事項のみを取り上げますが、インターネット上にはフラッシュストレージに関する幅広い種類の文献が存在します。例えば、Toradexの開発者向けウェブサイトには、ブログ、ウェビナーのアーカイブやさまざまな記事が掲載されています。フラッシュメモリーのウィキペディアの記事には、文字通り100件以上の参考文献やそのほかのリソースが記載されています。
NOR型とNAND型
フラッシュメモリーという用語は幅広いものを指します。いくつかの技術が組み合わせられ、最終的に特定の性質を持つフラッシュ製品となるためです。まず最初の区分として、フラッシュストレージにはNOR型とNAND型の2種が存在します。これらの名称は、ビットを格納するトランジスターのレベルで作動する技術の仕組みが、NORおよびNANDの論理ゲートに類似していることから付けられたものです。
NOR型は、NAND型と比較して動作上の原理がシンプルで安定性が高いのですが、必要なピン数が多く、シリコンのユニット領域当たりのストレージ密度が低いため、サイズとコストに悪影響を及ぼします。こうした理由から、多くの場合、非常に信頼性の高い産業グレードの組み込みシステムにおいてさえ、NOR型は最重要と見なされる特定のアプリケーションに限定して使用されます。このトピックについて詳しくは、Micronによる「NOR/NAND Flash Guide」(PDF)を参照してください。ストレージ密度と容量の側面から見たNOR型およびNAND型技術の概要を図4に示しました。これは、先述のガイドから引用したものです。
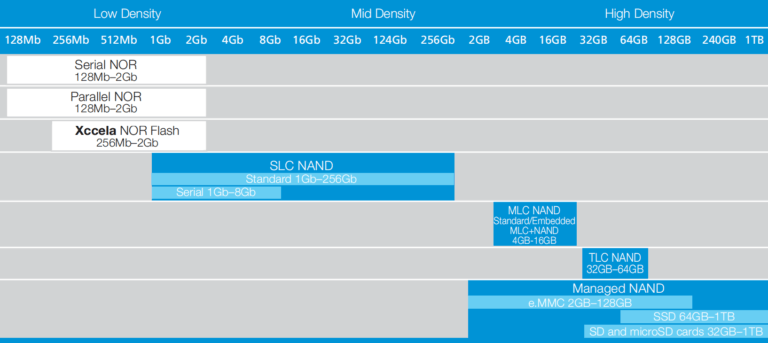
図 4:NOR型およびNAND型製品の密度と容量(出典:Micronの「NOR/NAND Flash Guide」)
ご覧のとおり、MicronのeMMCは、MLCとTLCの範囲ではすべてNANDデバイスとなっています。これについては後ほど詳述します。ToradexのSoMは、4GBから16GBの範囲のeMMCを搭載しているので、MLCデバイスを利用していると推察できます。このことについても、本記事で後に言及します。
NAND型構造
生のNAND型フラッシュデバイスは、3つの異なる部分に分けることができます。
- セル:最小の要素です。セルはビットレベルのデータを格納します。NAND型ストレージを制御するデバイスから直接アクセスすることはできません。
- ページ:セルの配列で、読み取りとプログラム操作のためにアクセス可能な最小単位です。プログラム操作は、ビットの値を1から0に「反転」させることです。ページのサイズは、4KBなどキロバイトの範囲になります。
- ブロック:ページの配列で、消去の操作においてアクセス可能な最小単位です。また、Linux MTDスタックなど一部のコンテキストによっては、ブロックは消去ブロックとしても知られています。消去操作は、ビットの値を0から1に戻すことです。ブロックのサイズは、4MBなどメガバイトの範囲になります。消去操作は、ページで行われるプログラム操作または読み取り操作と比較して大幅に時間がかかります。
- 消去操作は、時間の経過とともにフラッシュストレージを消耗させます。
- データ格納に利用できなくなったブロックは、不良ブロックとしてラベル付けされます。
これについて最も重要な点は、ブロックの消耗は消去によって起こる、ということです。このため、今回の論点でもっとも関心を向けたいのはブロック消去回数、つまり、各ブロックが消去された回数となります。

図 5:生のNANDフラッシュダイのハイレベル図。
NAND SLCおよびMLC
ビットは最小の要素であるセルに格納されます。セル1つ当たりに格納可能なビットの数は、セルが保持可能で、読み取り操作中に区別できる電圧のしきい値に依存します。フラッシュメモリーでは、各セルが保持できるビット数を示す区分がいくつかあります。
- SLC:シングルレベルセル。セル当たり1ビットを格納。
- pSLC:SLCモードで動作するMLCで、セル当たり1ビットを格納。
- MLC:マルチレベルセル。セル当たり2ビットを格納。
- TLC:トリプルレベルセル。セル当たり3ビットを格納。
- QLC:クアッドレベルセル。セル当たり4ビットを格納。
密度およびコストに対する信頼性と耐用期間の間にはトレードオフの関係があります。表1でこれを示しました。

表1: NANDセル技術の比較
図6では、SLCとMLCがビットを格納する仕組みを視覚化しました。
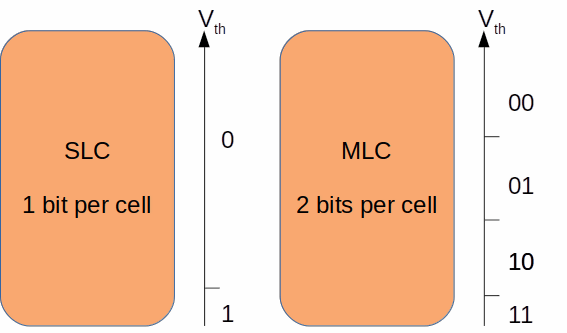
図6:SLCとMLCの電圧しきい値
pSLC(pseudo-SLC、疑似SLC)では、操作速度とMLCデバイスの寿命が向上しますが、代わりに容量が半分になります。実際のSLCの寿命にはかないませんが、寿命は大幅に延びます。疑似SLCをFastMode(高速モード)と混同しないようにしましょう。高速モードでは、MLCデバイスが高速になりますが、寿命は向上しません。
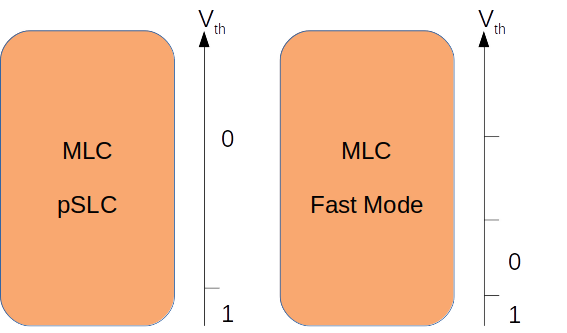
図7:擬似SLCと高速モード
ブロックがMLCまたはpSLCのいずれとして設定されているかを理解するのは、不良ブロックの数を経時的に収集してデバイスの耐用期間を判断する上で重要です。
MLC技術を採用したeMMCでは、ブロックの寿命は、シリコンのトレース幅によって平均3,000回から10,000回の消去サイクルになります。pSLCの耐用期間は、MLCと比較して2倍以上向上します。このため、高速モードやオーバープロビジョニング(容量が2倍のフラッシュメモリーを使用して耐用期間を2倍にする)を採用するよりも、pSLCの方が推奨されます。製造元が公表するドキュメントに消去サイクル数とトレース幅が記載されていないこともあり、解決策として、独自にデバイスのベンチマークを実施しなければならない場合もあります。
ECC
ブロックが消耗すると不良ブロックとなることについては、先に簡単に言及しました。しかし、ヘルスステータスが良好な場合にも、すべてが完璧に動作するとは限りません。ランダムにビットが反転され、格納されたデータが破損する可能性もあります。そうした場合には、ECC(誤り訂正符号)のアルゴリズムが機能して、反転したビットを訂正します。
ブロック内でビットが反転する確率は、時間が経過するにつれて高まります。この確率が高くなりすぎた時点で、ブロックは不良ブロックとしてマークされます。ブロックが早期に不良となることもあり、ストレージ装置には工場出荷時から不良ブロックが存在している場合もあります。製造元は、多くの場合、こうした不良ブロックに代わる予備のブロックを搭載することで、即座に使用可能なストレージ容量に影響が出ないようにしています。
書き込みの増幅
書き込みの増幅とは、簡単に言えば、あるブロックから別のブロックにデータを複製することです。データの更新、ウェアレベリングなどの目的で行われます。
ウェアレベリングとガベージコレクション
ファイルを更新する際などに、同じ物理ページとブロックを繰り返し使用していると、それらのブロックが早期に消耗してしまいます。NANDコントローラーがブロックの不良化とともにデータを移動させなければ、最悪の場合、フラッシュメモリーが寿命(EOL)を迎えるはるか前にシステムが動作しなくなってしまう可能性もあります。
この問題を防止するため、ウェアレベリングのアルゴリズムは、ブロックが常時、均等に利用されるようにします。均一な消耗を実現するため、データを移動させるのです。ウェアレベリングのアルゴリズムには2種類あります。
- ダイナミック:ダイナミックな(つまり経時的に更新される)データのみを移動します。スタティックなデータは元々書き込まれたブロックに保持されます。このアルゴリズムはシンプルですが、ストレージ装置全体の容量を使用しません。このアルゴリズムを採用するのに最適なのは、スタティックなデータを保持するフラッシュメモリーの割合が小さい場合です。
- スタティック:このアルゴリズムは、スタティックなデータを意図的に移動させて、フラッシュメモリーの全ブロックを均等に消耗させます。アルゴリズムはより複雑になりますが、利用可能なフラッシュメモリーすべてを使用することで、ストレージ装置の耐用期間を延ばします。
どのような理由であれデータを複製する際、そのブロックをすぐに消去するのではなく「汚れた」ブロックとしてマークするプロセスのことをガベージコレクションと言います。そして、その後のある時点で汚れたブロックの消去が実行されます。そのタイミングは、システムがそれらのブロックを必要とするまでの間で、システムが待機状態になった時点などです。先述しましたが、ブロックの消去は時間のかかる操作です。このため適切なガベージコレクションはパフォーマンスの向上につながる場合があります。
図8では、生のNANDの管理アルゴリズムを合わせてコントローラーとしてみなす様子を説明しています。このコントローラーは、物理消去ブロック(PEB)を論理消去ブロック(LED)にマッピングし、NANDに特有な操作をシンプルな「読み取り」と「書き込み」操作に抽象化します。

図8:生のNANDの操作は、コントローラーを介して抽象化されます。
NANDのプログラムや読み取り、書き込み操作を単純にHDDのような読み取りおよび書き込み操作へと変換する「賢くない」コントローラーを実装したシステムと生のNANDチップをインターフェースさせてしまうと、フラッシュメモリーのパフォーマンスと耐用期間に大幅な悪影響が出ます。ブロックデバイスにアクセスするファイルシステムでなく、生のNANDの特質を理解したファイルシステムが、さらにUBIとUBIFSのケースではその間のレイヤーが、ほぼ常にLinux MTDサブシステムを利用するのは、これが理由です。
ウェアレベリングの詳細について知りたい場合は、Micronの「TN-29-42: Wear-LevelingWear Leveling Techniques in NAND Flash Devices」(PDF)および「Wear leveling」に関するWikipediaの記事およびLWN.net記事など、Wikipediaの記事に記載された出典を参照してください。ガベージコレクションについては、Micronの「TN-2960: Garbage Collection in Single-Level Cell NAND Flash Memory」(PDF)をお読みください。
生のNANDデバイスとアプリケーションの間の抽象化レイヤーの完全な実装について詳細を理解するには、MTD、UBIおよびUBIFSの総合的ドキュメントを参照してください。もちろん、実装の仕様を理解するためには、Linux カーネルのソースコードを参照することもできます。
生のNAND操作は複雑ですが、消耗推定モデルを作成するにはある程度の理解が必要です。この複雑性を抽象化して取り除く簡単な方法は、コントローラーが内蔵されたマネージドNANDと呼ばれるNANDデバイスを購入することです。集積回路に限って言えば、よくあるタイプには、組み込みUSB、eMMCおよびUFSがあります。ここでは、eMMCに焦点を当てていきます。
eMMCフラッシュの詳細
産業グレードの組み込みシステムで最もよく利用される高容量フラッシュ技術はeMMC(Embedded MultiMedia Card)です。eMMCは、生のNANDダイ(通常はMLCまたはTLC)およびそれに付随するNANDコントローラーからなっています。下にあるオペレーティングシステムから管理ソフトウェアスタックの大部分を抽象化します。eMMC規格はJEDECによって管理されており、登録すればその情報に無償でアクセスできます。この記事執筆の時点で公表済みの最新規格はEmbedded MultiMedia Card Electrical Standard 5.1(登録後にPDFのダウンロードが可能)です。
コントローラーが高品質な抽象化レイヤーを提供するため、製造元の信頼性が高い限り、いくつかの注意を払っていれば、ブロックデバイス操作を理解するファイルシステムを安全に利用できます。Toradexの組み込みLinux BSPは、デフォルトで、eMMCフラッシュ搭載のコンピューターオンモジュールにEXT4ファイルシステムを利用します。図9は、コントローラーに関して、生のNANDとマネージドNANDの間の違いについて概略を示します。

図9:生のNANDおよびeMMCコントローラー
この記事で取り上げる例では、1024個のブロックを持つ4GBのMLC eMMCについて考えます。この実例としては、たとえばApalis iMX6Q 1GB SoMで採用されているMicronのMTFC4GACAJCN-1M-WTがあります。また、ブロックの平均寿命を3000回の消去サイクルと想定します。この数値は推測に過ぎず、先述した部品番号のデータシートから取ったものではありません。
eMMCを使用するにあたっての課題は、コントローラー実装とモジュールの耐用期間に関する詳細情報を集めることにあります。この情報は公開されている場合もされていない場合もあります。また、優れた独自ヘルスレポートを提供する製造元を優先して選択するのも一案です。eMMC規格では、この目的のためにレジスターを用意することになっていますが、使用は必須ではありません。このケーススタディーに選択したeMMCは詳細なヘルスレポートを提供します。ヘルスレポートに関する詳しい情報は、Micronの「TN-FC-32: e.MMC Device Health Report」で参照できます。これは、Micronのウェブサイトのe.MMC Softwareセクションに登録すると入手可能です。また、Micronのウェブサイトのこのセクションでは、この記事で後に利用するemmcparmツールおよび有益な「TN-FC-25: Understanding Linux Driver Support for e.MMC」も入手できます。
コマンドとレジスター
eMMC規格は、電力、CMD、DAT0-7およびCLKラインを含むバスを通じて操作を定義します。
CMDは、シリアルチャネルで、異なるCMDの値が異なる操作を表します。ホストからカードにコマンドが送信された後、同じシリアルラインを通じてカードからホストにレスポンスが送られます。関連データには、DATラインを通じてアクセスできます。興味がある方のために、複数ブロックの読み取り操作のイラストを図10で示します。幸い、ここで使用するすべてのツールではeMMC通信の実装、抽象化がすでに行われています。
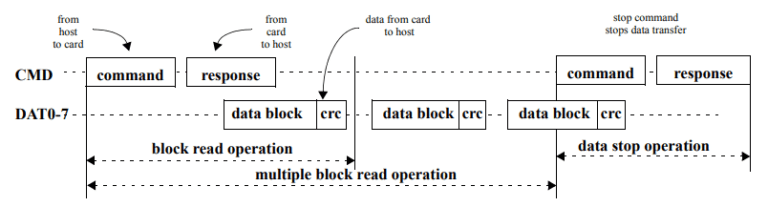
図10:複数ブロックの読み取り操作。(出典:JEDEC規格No. 84-B51、Section 5.3.1、9ページ目
eMMC規格は、さまざまな情報を持つレジスターも定義します。この情報へのアクセスは特定のCMDコマンドで行います。表2は、eMMCレジスターを表したものです。

表2:e.MMCレジスター(出典:JEDEC規格No. 84-B51、Chapter 5.3、8ページ目)
Extended Device Specific Data(旧称Extended Card Specific Data)は、ヘルスレポートにアクセスできる場所です。レポートには以下が含まれます。
- ベンダー独自のヘルスレポート。長さ32バイト。
- デバイス寿命推定タイプA。10%単位のヘルスステータスを提供。
- ここで使用するeMMCではSLCブロックに関連する値です。
- デバイス寿命推定タイプB。10%単位のヘルスステータスを提供。
- ここで使用するeMMCではMLCブロックに関連する値です。
- pre-EOLの情報。平均的な予約済みブロックによるデバイスの寿命を反映。
- 正常、警告(予約済みブロックの80%を消費済み)、緊急(予約済みブロックの90%を消費済み)の3つの値を返します。
ここで重要な疑問が生まれます。これらの情報を簡単に入手できるのであれば、なぜ、JEDEC規格によるこのデータを単に利用するだけでは不十分なのでしょうか?
- その理由の1つに、このヘルスレポートは、JEDEC規格の改訂バージョン5.0になって初めて追加されたことが挙げられます。
- また、値の精度が低く(10%単位)、少量のデータを書き込むベンチマークのアプリケーションには適さないことも理由の1つです。有益な情報を得るには、非常に長時間の実行が必要になってしまいます。
- さらに、特定の技術に依存しない手法を提供するフラッシュ消耗推定ツールの方が、SDカードやMTD上の生のフラッシュでも動作し、柔軟性の面で優れています。
Micron独自のヘルスレポート
このトピックについては、ほぼJEDEC規格の範疇外となります。唯一理解しなければならない情報は、このデータへのアクセス方法です。知っておくべきことは、このデータをシリコンから取り出すための入口として、General Command、つまりGEN_CMD、あるいはCMD56を利用しなければならないことです。eMMC仕様の「Application-specific commands」セクションで、詳しい情報を参照できます。
次に必要なのは、ベンダーによるヘルスレポートの実装に関する情報です。今回のケースでは、e.MMCソフトウェア関連のエリアで入手できる、Micronによる「TN-FC-32: e.MMC Device Health Report」に記載されています。
次のデータを取得できます
- 不良ブロック数および情報:工場出荷時の不良ブロック数、実行時の不良ブロック数、残っている予備ブロック数。また、障害の起きたページアドレスおよび障害が発生したのが消去またはプログラムのいずれだったのかについて、ブロックごとの情報を提供します。
- ブロック消去回数:すべてのブロックにおける最小、最大および平均のブロック消去回数、ならびにブロックごとの消去回数。
- ブロック構成:各ブロックの物理アドレス、各ブロックがSLCかMLCか。
各データへのアクセスには、特定の引数を使ってCMD56を発行します。
SoMの耐用期間にわたるeMMCのサポートに関する注意事項
SoM製造元の多くは、長期にわたって製品を入手可能とする方針を取っています。これは、産業または医療関連ユーザーなど、長期サポートによるメリットを得られる顧客を対象とすることが多いためです。たとえば、Toradexでは、製品が10年以上にわたって入手可能なことを保証しています。
SoM全体の寿命と比較した場合、個々のコンポーネントの寿命の方が短いことが多くなります。このため、時間の経過とともに新しいハードウェア改訂がリリースされ、これについては製品変更通知(PCN)で伝達されます。このことはSoMを利用する大きなメリットになります。再設計の複雑さが解消されるからです。
一方で、最新規格に適合しないeMMCを搭載したハードウェアが見つかることもあります。これも、特定の技術または規格に依存しない消耗推定ソリューションが必要とされる、実際的シナリオの一例です。
フラッシュのヘルスステータス
ある時点でのフラッシュのヘルスステータスは、全容量に対する消耗済み容量の割合とみなすことができます。話を単純化するため、ここでは、早期に消耗してしまうブロックがないこと、スタティックで最適なウェアレベリングが採用されていること、書き込みの増幅がないこと、言い換えれば理想的なシナリオであることを仮定します。
全体の耐久性は、消去回数の総計またはデバイスに書き込み可能なデータの総容量から得ることができます。

或者
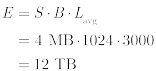
変数の説明:
- Eは、消去サイクル数(上の公式)またはバイト(下の公式)で表現される耐久性です。
- Bは、ブロックの数です。
- Lavgは、ブロック消去回数として表現された平均ブロック寿命です。
- Sは、バイト単位のブロックサイズです。
消去サイクルの総数の方が、その定義からして、耐久性をより正確に示します。ブロックの消耗はブロック消去によって起こるからです。このため、上の手法の方が下の手法よりも優れている傾向があります。
上記の例では、1,536,000回の消去がブロックに対して均等に発行された、または、デバイスに対して約6TBのデータが書き込まれた時点で、寿命の50%に達することになります。
フラッシュのヘルスステータスをLinuxで監視
Linuxで、先のセクションで説明したフラッシュのヘルスパラメーターを監視するには、eMMCデバイスから意味ある情報を抽出するソフトウェアが必要です。この目的のために利用できるオープンソースのツールに、mmc-utilsがあります。eMMCプロトコルの多くが実装されており、Extended Card Specific Data (EXT_CSD)レジスターからのデータ読み取りおよび人間が解読できる形式でのデータ表示も含まれます。JEDEC eMMC 5.0規格以降で定義されたデバイスの寿命も含まれます。6これについて、簡単に見てみましょう。パラメーターを指定せずにソフトウェアを実行してヘルプをプリントします。
root@colibri-imx6:~# mmc
Usage:
mmc extcsd read <device>
Print extcsd data from <device>.
mmc extcsd dump <device>
Print raw extcsd data from <device>.
上記の出力は、extcsd操作に焦点を当てています。extcsd readコマンドを実行すると、JEDECのヘルスステータスを含むさまざまな情報を取得できます。出力のヘッダー(最初の行)を見てみましょう。
root@colibri-imx6-05097264:/app# mmc extcsd read /dev/mmcblk1=============================================Extended CSD rev 1.7 (MMC 5.0)=============================================
これにより、JEDEC 5.0規格に従うeMMCであることを確認できます。次に、JEDECによって定義されたヘルスステータスを取得するため、出力をフィルタリングします。
root@colibri-imx6:~# mmc extcsd read /dev/mmcblk1 | grep LIFE
Device life time estimation type B [DEVICE_LIFE_TIME_EST_TYP_B: 0x01]
Device life time estimation type A [DEVICE_LIFE_TIME_EST_TYP_A: 0x01]
eMMC Life Time Estimation A [EXT_CSD_DEVICE_LIFE_TIME_EST_TYP_A]: 0x01
eMMC Life Time Estimation B [EXT_CSD_DEVICE_LIFE_TIME_EST_TYP_B]: 0x01
root@colibri-imx6-05097264:~# mmc extcsd read /dev/mmcblk1 | grep EOL
Pre EOL information [PRE_EOL_INFO: 0x01]
eMMC Pre EOL information [EXT_CSD_PRE_EOL_INFO]: 0x01
上記の例では、ヘルスステータスはデバイス寿命の0%から10%の間であることが推定され、pre-EOLステータスは正常です。よってこれは新しいデバイスです。ベンダー独自のヘルスレポートを取得した場合、アップストリームのmmc-utilsからは取得できないことがわかります。ChromiumOSダウンストリームでさえ、ゼロのみを表示します。
root@colibri-imx6:~# mmc-cos extcsd read /dev/mmcblk1 | grep -i healthVendor proprietary health report:[VENDOR_PROPRIETARY_HEALTH_REPORT[301]]: 0x00[VENDOR_PROPRIETARY_HEALTH_REPORT[300]]: 0x00[VENDOR_PROPRIETARY_HEALTH_REPORT[299]]: 0x00
とはいえ、このツールの機能を拡張するためのパッチを書くことは可能です。テストとして使用できる例として、次のようなものがあります。理解しやすいよう、コード全体は記載しません(検証は省かれています)。
/ Retrieve the erase count for each block// A two-step approach is needed (read number of tables and then read tables)int do_block_erase_info(int nargs, char **argv){ret = CMD56_data_in(fd, cmd56_how_many_tables, data_in);printf("Block erase count\n");printf("Block\tErase\n");for(table_idx = 0; table_idx < how_many_tables; table_idx++){ret = CMD56_data_in(fd, (table_idx * 256) + cmd56_retrieve_base, data_in);
for(physical_block = 0; physical_block < 128; physical_block++){printf("%d\t%d\n",(256*data_in[0+2*physical_block]) + data_in[1+2*physical_block],(256*data_in[256+2*physical_block]) + data_in[257+2*physical_block]);}}}
次にMicronのフラッシュから次のデータを取得するアプリケーションを実装できます。
int do_bad_block_count(int nargs, char **argv);
int do_bad_block_info(int nargs, char **argv);
int do_block_erase_count(int nargs, char **argv);
int do_block_erase_info(int nargs, char **argv);
int do_block_addr_type_info(int nargs, char **argv);
Micronのemmcparmなど、ベンダー独自のツールを使用するオプションもあります。こうしたツールは、総合的なJEDECのヘルスレポートだけでなく、先の実装提案で上記に示したような、より詳しいパラメーターを提供します。
この記事執筆の時点(2019年8月)では、2016年5月27日にリリースされたバージョン2.6.0(あるいは、Micronからは入手不可能となっているこれよりも古いバージョン)から、2019年6月5日にリリースされたバージョン4.4.0まで、emmcparmは定期的に更新され続けています。このツールにはいくつかの関数があり、その一部がヘルスステータスに関連しています。
root@colibri-imx6:~# emmcparm_arm
--spare_block
--bad_block
--erase_count
--sect_count
I/Oトラッキング
I/Oトラッキングは、フラッシュの早期消耗を示唆する有益な指標となります。また、過多なデータ書き込みを行っているアプリケーションを特定するデバッグにも利用できます。I/Oトラッキングによって、JEDEC規格またはeMMCベンダーのヘルスレポートに依存しない消耗推定モデルの入力データの生成が可能になります。このため、生のNANDをストレージ技術に採用する多様な技術に拡張可能な、柔軟性のあるツールを実現する手法となります。/p>
信頼性の高いI/Oトラッキングの仕組みを実装するには、まず、Linux I/Oスタックがどのように動作するかについての基礎知識を習得する必要があります。通常アプリケーション開発で行われることをハイレベルで見た場合、プログラマーがユーザー空間でコードを書き、ファイル操作が行われます。/p>
操作が行われる仕組みは、使用するライブラリーや言語によって異なりますが、どこかの時点でユーザー空間からカーネル空間への移行が起こります。この時点で、ライブラリーの関数がカーネルに対するシステムコールを行います。自分でシステムコールを行うことも可能ですが、C標準ライブラリーなどの検証が重ねられ成熟したライブラリーを使用する場合と比較して、抽象化が除去されて、エラーが起こりやすくなります。/p>
次にLinuxのカーネルが、通常はI/Oスタックまたはストレージスタックと呼ばれるものを通じてI/Oを処理します。最後のステップとして、低レベルのドライバーを通じてデバイスへとデータが送信されます。このドライバーは、eMMCの場合、JEDEC規格に準拠している必要があります。図11では、生のNANDおよびeMMCデバイスのスタックについて可能な限りハイレベルに図解しました。/p>
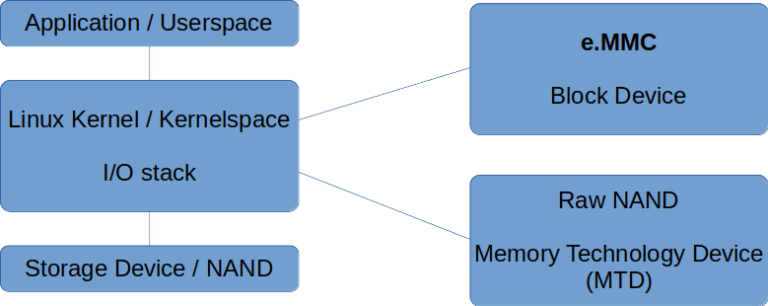
図11:eMMCと生のNANDのI/Oスタック
カーネルスタックについて最上部から下部へ向かって見ていきます。
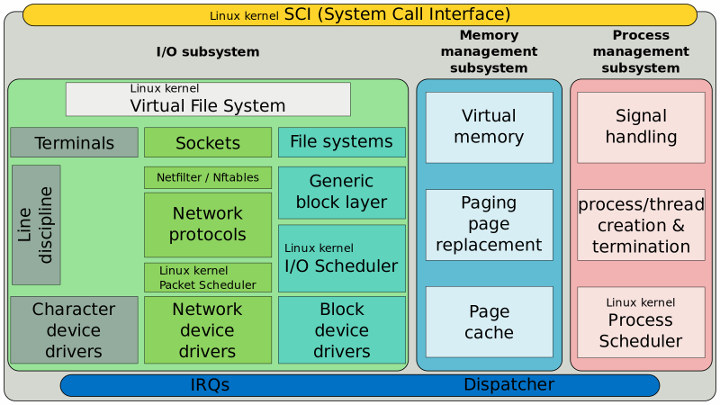
図12:Linuxカーネルの構造を簡単に示した概要図。(出典:Wikipedia)
- Virtual file system(仮想ファイルシステム)は、ユーザー空間APIのための抽象化レイヤーです。
- File system(ファイルシステム)は、ファイル関連の概念を定義する特定構造を実装します。
- Generic block layer(汎用ブロックレイヤー)は、多くの文献ではI/O scheduler(I/Oスケジューラー)を含むレイヤーで、スタックにおいてすべてのブロックI/O(BIO)が処理される場です。従ってファイルシステムに対するブロックデバイスの抽象化などが行われます。
- I/O scheduler(I/Oスケジューラー)は、特定のアルゴリズムに従ってI/Oリクエストのキューを処理し、block device driver(ブロックデバイスドライバー)へと送信します。ブロックI/Oのパフォーマンスの最大化を目的としており、選択するスケジューラーによって、レイテンシー、スループットやフラッシュメモリー使用に影響が出ます。
書き込み率取得のためにフラッシュへの書き込み回数を経時的に観測することは、ユーザー空間から実施可能であり、それで十分だと考えるかもしれません。しかし、このアプローチの最大の問題点は、正確な測定ができないことにあります。
図13に示すように、Linuxカーネルは、際限ないディスクアクセスを防ぐためスタックを通じてキャッシュのレイヤーを複数実装した複雑なシステムとなっています。これまでの懸念は、ディスク操作が時間のかかるものだったことに起因していました。フラッシュの出現によって高速な動作は実現した現在では、ストレージ装置の耐用期間を延長させる必要性が生まれました。これを助けるのがキャッシュとキューです。

図13:キャッシュ、バッファー、キューと同期。
Linuxのカーネルは、ページキャッシュと呼ばれるキャッシュを実装しており、これは、ハイレベルなVFSとローレベルのファイルシステムの間に存在します。カーネルで最も利用されるキャッシュシステムです。ユーザー空間のアプリケーションで、ファイルシステムを通さず、すぐにデータを利用できるようにします。
I/Oスタックの深部では、I/Oのマージによるキャッシング効果が発生することがあります。これは、ストレージハードウェア利用の最適化、通常スループット向上のためのI/Oキューの最適化によるものです。I/Oのマージ例としては、絶対に必要となるまでデータを保持する書き戻しの仕組みがあり、これによってフラグメント化を回避し、ページやブロックの一部のみが利用されるのを防ぎます。これらの仕組みがあるため、特定のプロセスによる書き込みが、どれほどの割り合いで実際にフラッシュメモリーに到達しているかを追跡するのは困難な作業となります。
ちなみに、データ同期について一つ言及しておきます。これは、組み込みシステムのユースケース(特に予備電力がないもの)にとって非常に重要で、フラッシュの耐用期間に影響する可能性があることですが、電力停止が発生した場合でも、同期を行うのはデータをどうしても保存しなければならない場合のみにするよう注意する必要があります。マシンのタッチスクリーンでユーザーが「保存」を押した際などが、そうした場合の一例です。
I/O書き込みの測定
実際にフラッシュメモリーに到達するすべての書き込みを監視し測定するという観点から見ていくと、問題はより明確になります。
- Linuxスタックのどこならば、フラッシュメモリーに到達する書き込みを測定できるのでしょうか?
- 測定するにはどうすればよいのでしょうか?(どのようなツールを利用できるのでしょうか?)
データ収集に利用できるツールの数が限られているヘルスステータスの測定とは異なり、Linuxカーネルのスタックの監視に利用できるツールは数多く存在します。この一例は、Brendan Greggのブログから転載した図14に示されています。Brendan Greggは、Linuxのパフォーマンス監視の分野で最も深い知識を持った専門家の1人です。
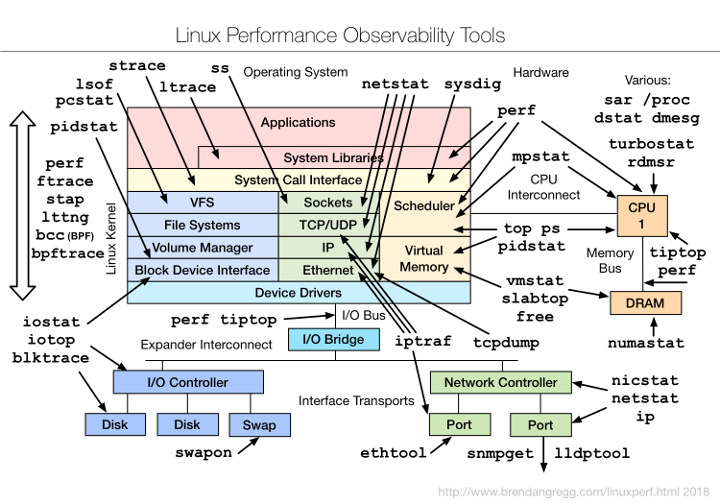
図14:Linuxのパフォーマンス監視ツール。(出典:Brendan Greg)
リサーチを進める中で、この課題に利用できる候補を2つ見つけました。ユーザー空間操作のトラッキングに利用可能なiotopと、ブロックレベルのI/Oおよび実際にフラッシュメモリーに到達するものを正確にトラッキングできるblktrace/blkparseです。本記事の著者はカーネルのハッカーではなく、このトピックに関してはさらなるリサーチの余地が多く残っているため、この2つのツールが本目的のための最良で最適なツールあることを示唆している訳ではありません(例えば、perfトレースとeBPFについても試用したいと考えています)。この件に関しては、Linux block I/O tracingという興味深い記事があり、Linuxカーネルのドキュメント自体など、インターネット上にはほかにも数多くのリソースが存在します。
ブロックレベルでのI/Oトラッキングが大切なのは、それが正確な方法だからです。キャッシュからフラッシュされたりカーネル内で次のファイルシステム操作によってマージされたりするのではなく、書き込み操作が実際にフラッシュメモリーに到達したことを確実に知るにはブロックレベルでI/Oをトラッキングするほかありません。これが重要なのは、本当に確認しなければならないのは、アプリケーションが書き込もうとしたデータの量だけでなく、ブロックが書き込まれた(実際には消去された)回数であるためです。
iotopとblktraceを実際にどのように利用できるのか、簡単に見てみましょう。
iotopには、この作業に役立つ便利なオプションがあり、タイムスタンプ、書き込み回数、書き込みを実行したプロセスについての情報収集と処理を簡単に行えます。
root@colibri-imx6:~# iotop –help
Options:
-o, --only only show processes or threads actually doing I/O
-b, --batch non-interactive mode
-a, --accumulated show accumulated I/O instead of bandwidth
-k, --kilobytes use kilobytes instead of a human friendly unit
-t, --time add a timestamp on each line (implies –batch)
-q, --quiet suppress some lines of header (implies --batch)
以下に例を示します
root@colibri-imx6:~# dd if=/dev/urandom bs=4k count=100000 | pv -L 25k > testfile
root@colibri-imx6:~# iotop --only --batch --accumulated --kilobytes --time –quietTIME TID PRIO USER DISK READ DISK WRITE SWAPIN IO COMMAND2019-08-02 03:11:19 50 be/4 root 0.00 K 24.00 K -0.00 % -0.00 % pv -L 25k2019-08-02 03:11:20 50 be/4 root 0.00 K 52.00 K -0.00 % -0.00 % pv -L 25k2019-08-02 03:11:21 50 be/4 root 0.00 K 80.00 K -0.00 % -0.00 % pv -L 25k2019-08-02 03:11:22 50 be/4 root 0.00 K 104.00 K -0.00 % -0.00 % pv -L 25k2019-08-02 03:11:23 50 be/4 root 0.00 K 128.00 K -0.00 % -0.00 % pv -L 25k
一方のblktraceでは、ことはもう少し複雑になります。手始めにドキュメントを参照してみます。フィルターを使わずにライブモードで実行すると、圧倒されるほど大量の情報が出力されます。
root@colibri-imx6:~# blktrace -o - /dev/mmcblk1 | blkparse -i -179,0 0 26 0.000114661 304 A WS 4509800 + 8 <- (179,2) 4468840179,0 0 27 0.000117328 304 Q WS 4509800 + 8 [jbd2/mmcblk1p2-]179,0 0 28 0.000119661 304 M WS 4509800 + 8 [jbd2/mmcblk1p2-]179,0 0 29 0.000127328 304 U N [jbd2/mmcblk1p2-] 1179,0 0 30 0.000131661 304 I WS 4509736 + 72 [jbd2/mmcblk1p2-]179,0 0 31 0.008860277 279 D WS 4509736 + 72 [kworker/0:3H]179,0 0 32 0.012586780 279 C WS 4509736 + 72 [0]
幸い、blktraceおよびblkparseの双方ではフィルターが実装されているので、作業は簡単です。表3で、フィルターのリストと簡単な説明を示します。

表3:フィルターマスク(出典:blktraceのマニュアル)
ユーザー空間のPID情報の最終ポイントとフラッシュメモリーに対する確定書き込み操作をトラックするには、writeフィルターを利用します。blkparseの側では、さらに追加のフィルターにより次の追跡アクションを選択できます。以下はblkparseのドキュメントから引用したものです。
- C – Complete:以前に発行された要求が完了されました。要求のセクターおよびサイズの詳細と要求の成功または失敗について出力します。
- I – Inserted:要求はI/Oスケジューラーに送信され、内部キューおよび後にドライバーによってサービス
耐用期間の推定
I/Oトラッキングとフラッシュのヘルスを記録することで、2つの相関関係を判断できます。
- 経時的なフラッシュのヘルス
- 書き込み率に対するフラッシュのヘルス
双方の相関関係は時間の経過とともに現れるものです。このため、別のストレージメディア上に(または自身のフラッシュ消耗も考慮した上で同じメディア上に)ローカルDBを実装し、十分な時間をかけてシステムを実行することで、上記の相関関係を推定し、耐用期間を計算するのに十分なデータを収集します。
耐久性を消去サイクル数で示した場合:
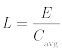
耐久性をバイト数またはその倍数で示した場合:

変数の説明:
- Lは秒単位での耐用期間です。
- Eは、消去サイクル数(上の公式)またはバイト数(下の公式)を単位とした耐久性です。
- Cavgは、平均の全ブロック消去回数で、1秒当たりのブロック消去の合計回数をブロック数で割った数です。
- Wavgは、調整された、バイト数を単位とした平均書き込み率です。
2番目の公式による、調整された平均書き込み率は、フラッシュヘルスの書き込み率に対する相関関係を考慮した上での書き込み率であることに留意してください。したがって、書き込みの増幅、ディスクへのシステム書き込みなど、アプリケーションの観点からの監視や論理上の値の測定を行う場合には考慮されない要素も、実際には考慮に入れることになります。
消耗に関するそのほかの事項
温度もフラッシュの耐用期間に影響を与えます。利用可能な場合のpSLCモードの使用や、スタティックまたはダイナミックウェアレベリングの使用、不良ブロックの存在、デバイスが寿命に近づいた場合に何が起こるのか、また予備ブロックの存在などについても考慮しなければなりません。
文献を熟読して、注意すべき事項やモデルに影響する可能性のあるそのほかの側面を洗い出してください。
まとめ
フラッシュの耐用期間を推定するには、フラッシュヘルスによって提供されるブロックサイズの公式で計算する単純な方法、または、ツールを実装してモデルを生成し、デバイスの耐用期間の秒数を推定する方法が考えられます。どれほどの労力を費やすかどうかは、製品のユースケースに応じて決定可能で、図16で概説したように重要な要素のみを選択できます。いずれにしても、これは価値ある情報です。
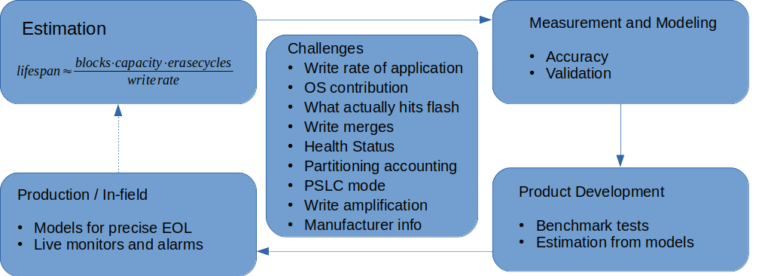
図16:生のNANDの耐用期間の推定と予測。
複雑なアプローチには、単純な計算と比較して一定のメリットがあります。より正確な結果が得られる上、独自のツールを実稼働環境に導入して、さらに精度の高い寿命データを取得することができます。これにより、監視機能、さらに、警告通知を出して予測に基づいた保守を実現する機能の提供も可能になります。Micronのemmcparm、mmc-utilsおよローレベルからハイレベルまでのさまざまなツールを利用すれば、信頼性の高いソリューションを作成する労力を軽減できます。最後までお読みいただき、ありがとうございました。
このブログはもともとCNXSoftで投稿されました。 Marcelは、Embedded Linux Conference 2019で「eMMCフラッシュメモリー搭載デバイスの消耗推定」と題して講演を行いました。
Authors:
Marcel Ziswiler, Platform Manager – Embedded Linux
Leonardo Graboski Veiga, Technical Marketing Engineer
Marcel Ziswiler, Platform Manager – Embedded Linux
Leonardo Graboski Veiga, Technical Marketing Engineer
Leave a comment
Please login to leave a comment!
Latest Blog
Friday, April 5, 2024
Tuesday, March 19, 2024
Friday, January 12, 2024